Ruff supports more than `known-first-party`, `known-third-party`, `extra-standard-library`, and `src` nowadays.
Not sure if this is the best wording. Suggestions welcome!
Extend test fixture to verify the targeting.
Includes two "attribute docstrings" which per PEP 257 are not recognized by the Python bytecode compiler or available as runtime object attributes. They are not available for us either at time of writing, but include them for completeness anyway in case they one day are.
To enable ruff_dev to automatically generate the rule Markdown tables in
the README the ruff library contained the following function:
Linter::codes() -> Vec<RuleSelector>
which was slightly changed to `fn prefixes(&self) -> Prefixes` in
9dc66b5a65 to enable ruff_dev to split
up the Markdown tables for linters that have multiple prefixes
(pycodestyle has E & W, Pylint has PLC, PLE, PLR & PLW).
The definition of this method was however largely redundant with the
#[prefix] macro attributes in the Linter enum, which are used to
derive the Linter::parse_code function, used by the --explain command.
This commit removes the redundant Linter::prefixes by introducing a
same-named method with a different signature to the RuleNamespace trait:
fn prefixes(&self) -> &'static [&'static str];
As well as implementing IntoIterator<Rule> for &Linter. We extend the
extisting RuleNamespace proc macro to automatically derive both
implementations from the Linter enum definition.
To support the previously mentioned Markdown table splitting we
introduce a very simple hand-written method to the Linter impl:
fn categories(&self) -> Option<&'static [LinterCategory]>;
ParseCode was a fitting name since the trait only contained a single
parse_code method ... since we now however want to introduce an
additional `prefixes` method RuleNamespace is more fitting.
Using Ident as the key type is inconvenient since creating an Ident
requires the specification of a Span, which isn't actually used by
the Hash implementation of Ident.
If a file doesn't have a `package`, then it must both be in a directory that lacks an `__init__.py`, and a directory that _isn't_ marked as a namespace package.
Closes#2075.
- optional `prefix` argument for `add_plugin.py`
- rules directory instead of `rules.rs`
- pathlib syntax
- fix test case where code was added instead of name
Example:
```
python scripts/add_plugin.py --url https://pypi.org/project/example/1.0.0/ example --prefix EXA
python scripts/add_rule.py --name SecondRule --code EXA002 --linter example
python scripts/add_rule.py --name FirstRule --code EXA001 --linter example
python scripts/add_rule.py --name ThirdRule --code EXA003 --linter example
```
Note that it breaks compatibility with 'old style' plugins (generation works fine, but namespaces need to be changed):
```
python scripts/add_rule.py --name DoTheThing --code PLC999 --linter pylint
```
## Summary
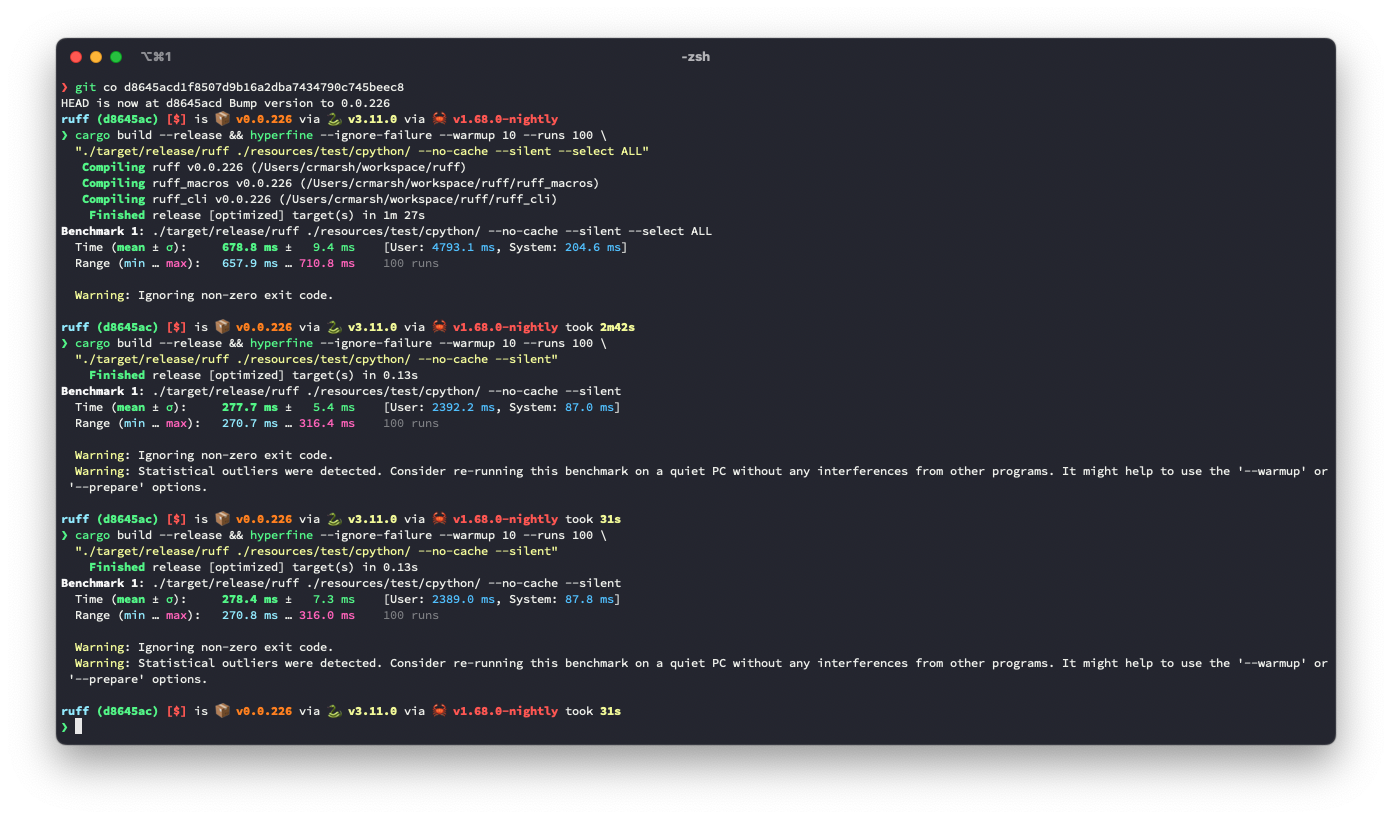
The problem: given a (row, column) number (e.g., for a token in the AST), we need to be able to map it to a precise byte index in the source code. A while ago, we moved to `ropey` for this, since it was faster in practice (mostly, I think, because it's able to defer indexing). However, at some threshold of accesses, it becomes faster to index the string in advance, as we're doing here.
## Benchmark
It looks like this is ~3.6% slower for the default rule set, but ~9.3% faster for `--select ALL`.
**I suspect there's a strategy that would be strictly faster in both cases**, based on deferring even more computation (right now, we lazily compute these offsets, but we do it for the entire file at once, even if we only need some slice at the top), or caching the `ropey` lookups in some way.
Before:
After:
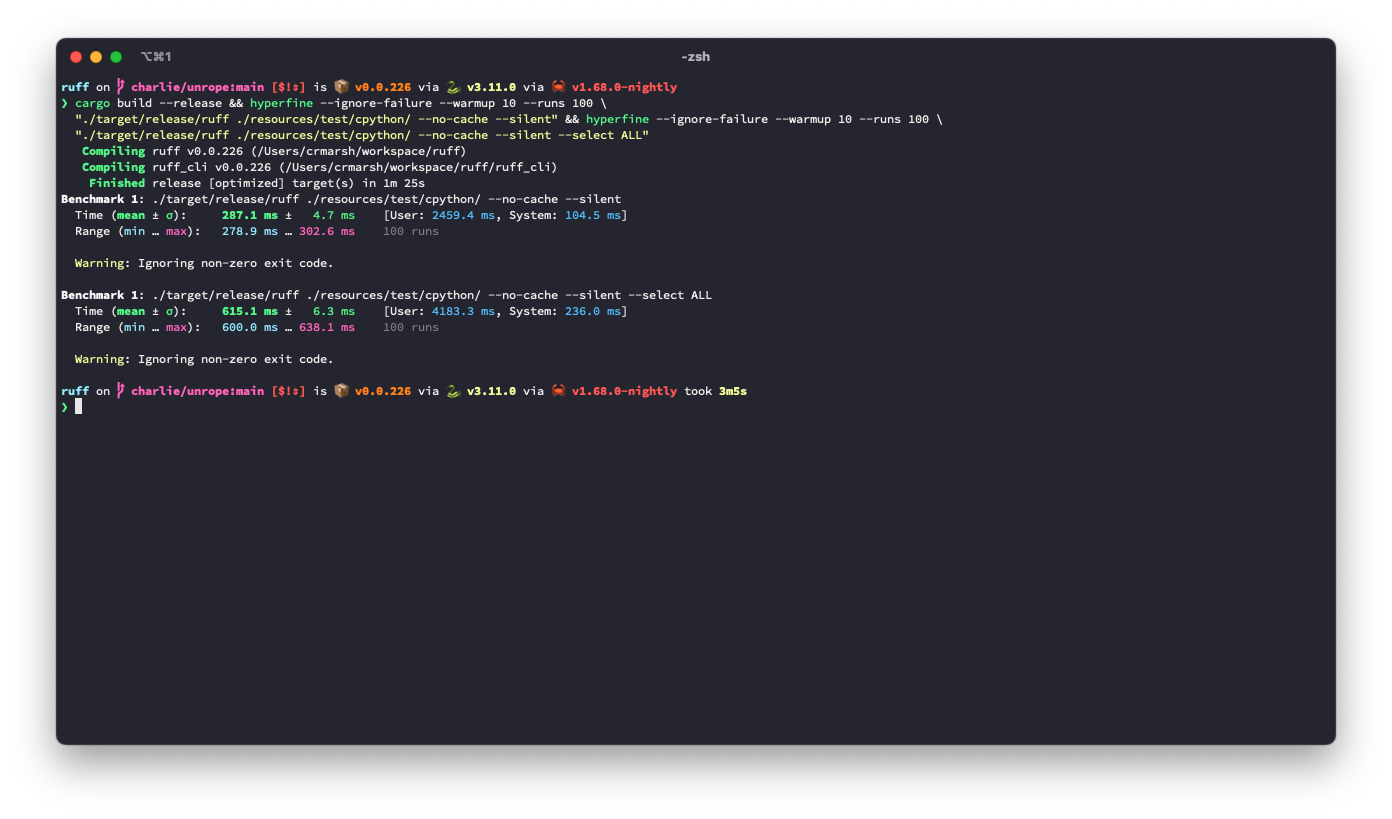
## Alternatives
I tried tweaking the `Vec::with_capacity` hints, and even trying `Vec::with_capacity(str_indices::lines_crlf::count_breaks(contents))` to do a quick scan of the number of lines, but that turned out to be slower.
Add tests.
Ensure that these cases are caught by ICN001:
```python
from xml.dom import minidom
from xml.dom.minidom import parseString
```
with config:
```toml
[tool.ruff.flake8-import-conventions.extend-aliases]
"dask.dataframe" = "dd"
"xml.dom.minidom" = "md"
"xml.dom.minidom.parseString" = "pstr"
```
{kind=link}
{kind=link}