I think we've never run into this case, since it's rare to import `*` from a module _and_ import some other member explicitly. But we were deviating from `isort` by placing the `*` after other members, rather than up-top.
Closes#2318.
`RUF100` does not take into account a rule ignored for a file via a `per-file-ignores` configuration. To see this, try the following pyproject.toml:
```toml
[tool.ruff.per-file-ignores]
"test.py" = ["F401"]
```
and this test.py file:
```python
import itertools # noqa: F401
```
Running `ruff --extend-select RUF100 test.py`, we should expect to get this error:
```
test.py:1:19: RUF100 Unused `noqa` directive (unused: `F401`)
```
The issue is that the per-file-ignores diagnostics are filtered out after the noqa checks, rather than before.
Accessed attributes that are Python constants should be considered for yoda-conditions
```py
## Error
JediOrder.YODA == age # SIM300
## OK
age == JediOrder.YODA
```
~~PS: This PR will fail CI, as the `main` branch currently failing.~~
SIM300 currently doesn't take Python constants into account when looking for Yoda conditions, this PR fixes that behavior.
```python
# Errors
YODA == age # SIM300
YODA > age # SIM300
YODA >= age # SIM300
# OK
age == YODA
age < YODA
age <= YODA
```
Ref: <https://github.com/home-assistant/core/pull/86793>
This isn't super consistent with some other rules, but... if you have a lone body, with a `pass`, followed by a comment, it's probably surprising if it gets removed. Let's retain the comment.
Closes#2231.
Extend test fixture to verify the targeting.
Includes two "attribute docstrings" which per PEP 257 are not recognized by the Python bytecode compiler or available as runtime object attributes. They are not available for us either at time of writing, but include them for completeness anyway in case they one day are.
If a file doesn't have a `package`, then it must both be in a directory that lacks an `__init__.py`, and a directory that _isn't_ marked as a namespace package.
Closes#2075.
## Summary
The problem: given a (row, column) number (e.g., for a token in the AST), we need to be able to map it to a precise byte index in the source code. A while ago, we moved to `ropey` for this, since it was faster in practice (mostly, I think, because it's able to defer indexing). However, at some threshold of accesses, it becomes faster to index the string in advance, as we're doing here.
## Benchmark
It looks like this is ~3.6% slower for the default rule set, but ~9.3% faster for `--select ALL`.
**I suspect there's a strategy that would be strictly faster in both cases**, based on deferring even more computation (right now, we lazily compute these offsets, but we do it for the entire file at once, even if we only need some slice at the top), or caching the `ropey` lookups in some way.
Before:
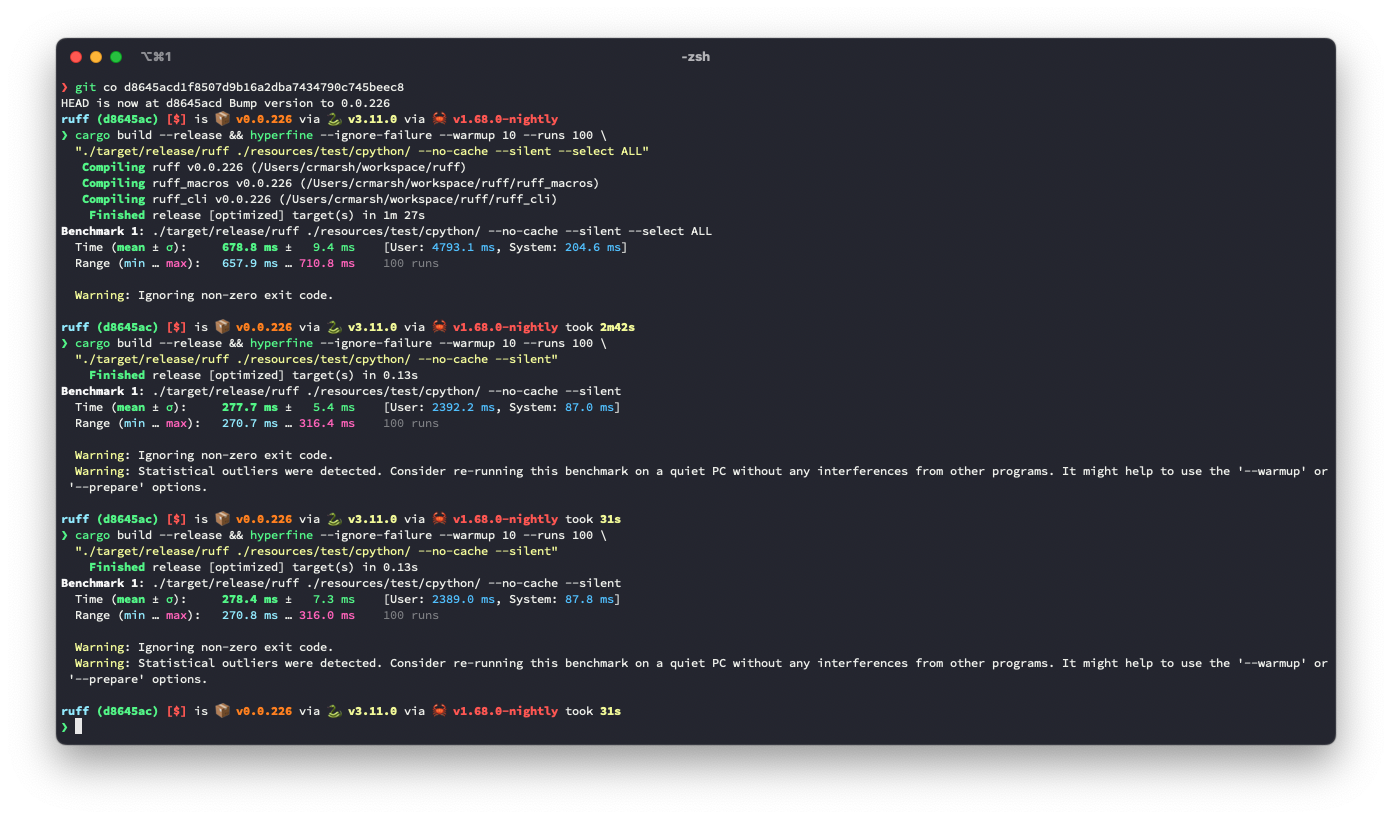
After:
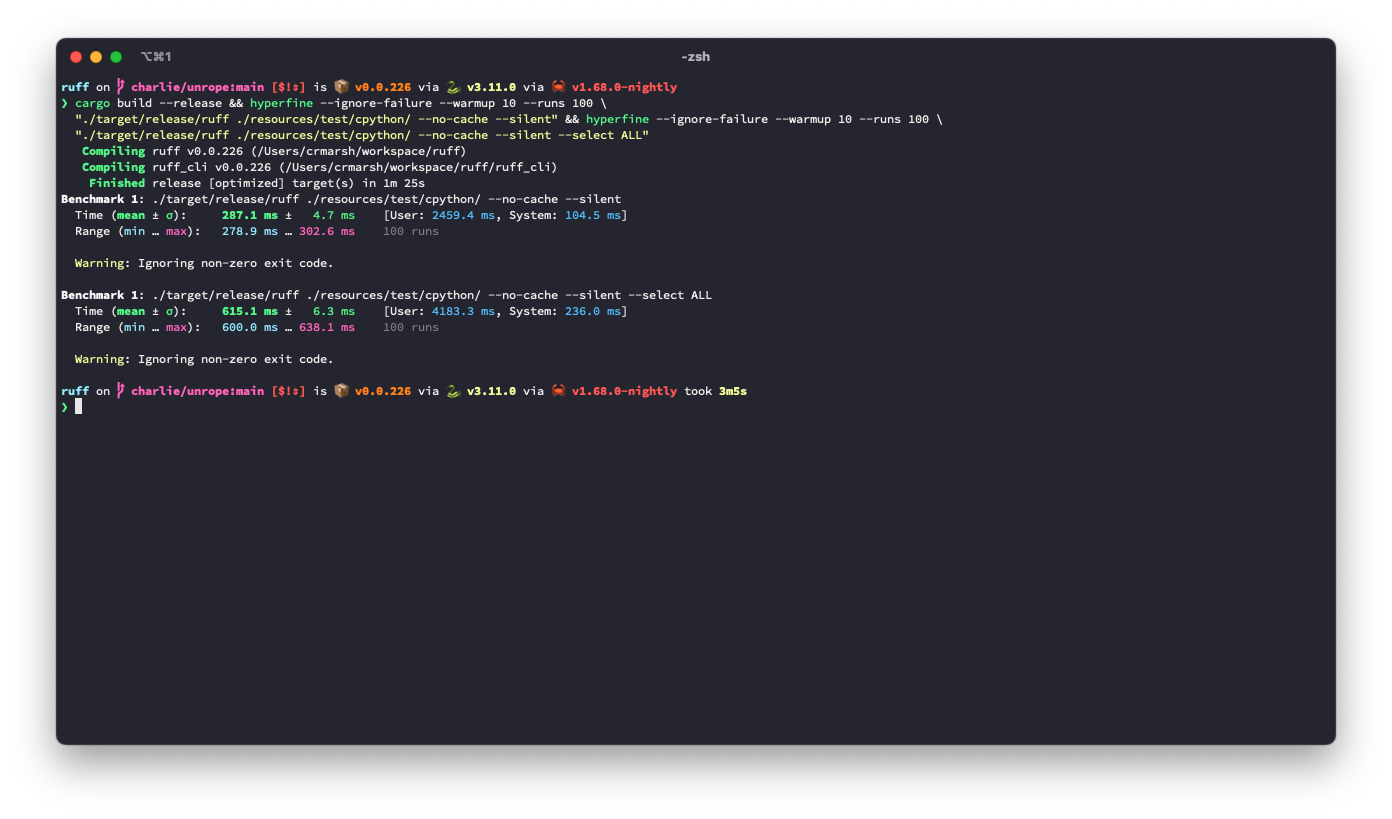
## Alternatives
I tried tweaking the `Vec::with_capacity` hints, and even trying `Vec::with_capacity(str_indices::lines_crlf::count_breaks(contents))` to do a quick scan of the number of lines, but that turned out to be slower.
{kind=link}
{kind=link}