mirror of
https://github.com/astral-sh/uv.git
synced 2025-07-07 13:25:00 +00:00
Lint
This commit is contained in:
parent
9ba5b249f9
commit
f25c67e181
1 changed files with 43 additions and 18 deletions
|
|
@ -7,13 +7,16 @@ description:
|
||||||
|
|
||||||
# Using uv with Coiled
|
# Using uv with Coiled
|
||||||
|
|
||||||
[Coiled](https://coiled.io?utm_source=uv-docs) is a serverless, UX-focused cloud computing platform that makes it easy to run code on cloud hardware (AWS, GCP, and Azure).
|
[Coiled](https://coiled.io?utm_source=uv-docs) is a serverless, UX-focused cloud computing platform
|
||||||
|
that makes it easy to run code on cloud hardware (AWS, GCP, and Azure).
|
||||||
|
|
||||||
This guide shows how to run Python scripts on the cloud using uv for software dependency management and Coiled for cloud deployment.
|
This guide shows how to run Python scripts on the cloud using uv for software dependency management
|
||||||
|
and Coiled for cloud deployment.
|
||||||
|
|
||||||
## Managing software with uv
|
## Managing software with uv
|
||||||
|
|
||||||
Here's a `process.py` script that uses [`pandas`](https://pandas.pydata.org/docs/) to load a Parquet data file hosted in a public bucket on S3 and prints the first few rows:
|
Here's a `process.py` script that uses [`pandas`](https://pandas.pydata.org/docs/) to load a Parquet
|
||||||
|
data file hosted in a public bucket on S3 and prints the first few rows:
|
||||||
|
|
||||||
```python title="process.py"
|
```python title="process.py"
|
||||||
|
|
||||||
|
|
@ -26,9 +29,12 @@ df = pd.read_parquet(
|
||||||
print(df.head())
|
print(df.head())
|
||||||
```
|
```
|
||||||
|
|
||||||
We'll use this concrete example throughout the rest of the guide, but know that the script contents could be _any_ Python code.
|
We'll use this concrete example throughout the rest of the guide, but know that the script contents
|
||||||
|
could be _any_ Python code.
|
||||||
|
|
||||||
Running this script requires `pandas`, `pyarrow`, and `s3fs`. uv makes it easy to embed these dependencies directly in the script using [PEP 273](https://peps.python.org/pep-0723/) inline metadata with the [`uv add --script` command](../scripts.md#declaring-script-dependencies).
|
Running this script requires `pandas`, `pyarrow`, and `s3fs`. uv makes it easy to embed these
|
||||||
|
dependencies directly in the script using [PEP 273](https://peps.python.org/pep-0723/) inline
|
||||||
|
metadata with the [`uv add --script` command](../scripts.md#declaring-script-dependencies).
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ uv add --script process.py pandas pyarrow s3fs
|
$ uv add --script process.py pandas pyarrow s3fs
|
||||||
|
|
@ -62,7 +68,8 @@ We then use `uv run` to run the script locally
|
||||||
$ uv run process.py
|
$ uv run process.py
|
||||||
```
|
```
|
||||||
|
|
||||||
uv automatically creates a virtual environment, installs the dependencies, and then runs `process.py` in that environment. Here's the output we get:
|
uv automatically creates a virtual environment, installs the dependencies, and then runs
|
||||||
|
`process.py` in that environment. Here's the output we get:
|
||||||
|
|
||||||
```
|
```
|
||||||
hvfhs_license_num dispatching_base_num originating_base_num request_datetime on_scene_datetime ... shared_request_flag shared_match_flag access_a_ride_flag wav_request_flag wav_match_flag
|
hvfhs_license_num dispatching_base_num originating_base_num request_datetime on_scene_datetime ... shared_request_flag shared_match_flag access_a_ride_flag wav_request_flag wav_match_flag
|
||||||
|
|
@ -76,9 +83,12 @@ __null_dask_index__
|
||||||
[5 rows x 24 columns]
|
[5 rows x 24 columns]
|
||||||
```
|
```
|
||||||
|
|
||||||
What's nice about this is we didn't have to think about managing local virtual environments ourselves and the dependencies needed are included directly in the script which makes things nicely self-contained.
|
What's nice about this is we didn't have to think about managing local virtual environments
|
||||||
|
ourselves and the dependencies needed are included directly in the script which makes things nicely
|
||||||
|
self-contained.
|
||||||
|
|
||||||
That's really all we need for running scripts locally. However, there are many common use cases where resources beyond what's available on our local workstation are needed, like:
|
That's really all we need for running scripts locally. However, there are many common use cases
|
||||||
|
where resources beyond what's available on our local workstation are needed, like:
|
||||||
|
|
||||||
- Processing large amounts of cloud-hosted data
|
- Processing large amounts of cloud-hosted data
|
||||||
- Needing accelerated hardware like GPUs or a big machine with more memory
|
- Needing accelerated hardware like GPUs or a big machine with more memory
|
||||||
|
|
@ -88,9 +98,13 @@ In these situations running scripts directly on cloud hardware is often a good s
|
||||||
|
|
||||||
## Running on the cloud with Coiled
|
## Running on the cloud with Coiled
|
||||||
|
|
||||||
Similar to how uv makes it straightforward to handle Python dependency management, Coiled makes it straightforward to handle running code on cloud hardware.
|
Similar to how uv makes it straightforward to handle Python dependency management, Coiled makes it
|
||||||
|
straightforward to handle running code on cloud hardware.
|
||||||
|
|
||||||
Let's start by authenticating whatever machine you're running on with Coiled using the [`coiled login` CLI](https://docs.coiled.io/user_guide/api.html?utm_source=uv-docs#coiled-login) (you'll be prompted to create a Coiled account if you don't already have one -- and it's totally free to start using Coiled):
|
Let's start by authenticating whatever machine you're running on with Coiled using the
|
||||||
|
[`coiled login` CLI](https://docs.coiled.io/user_guide/api.html?utm_source=uv-docs#coiled-login)
|
||||||
|
(you'll be prompted to create a Coiled account if you don't already have one -- and it's totally
|
||||||
|
free to start using Coiled):
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ uvx coiled login
|
$ uvx coiled login
|
||||||
|
|
@ -128,9 +142,18 @@ df = pd.read_parquet(
|
||||||
print(df.head())
|
print(df.head())
|
||||||
```
|
```
|
||||||
|
|
||||||
They tell Coiled to use the official [uv Docker image](https://github.com/astral-sh/uv/pkgs/container/uv) when running the script (this makes sure uv is installed) and to run the script in the ``us-east-2`` region on AWS (where this data file happens to live) to avoid any data egress. There are several other options we could have specified here like VM instance type (the default is a 4-core VM with 16 GiB of memory), whether to use spot instance, etc. See the [Coiled Batch docs](https://docs.coiled.io/user_guide/batch.html?utm_source=uv-docs) for more details.
|
They tell Coiled to use the official
|
||||||
|
[uv Docker image](https://github.com/astral-sh/uv/pkgs/container/uv) when running the script (this
|
||||||
|
makes sure uv is installed) and to run the script in the `us-east-2` region on AWS (where this data
|
||||||
|
file happens to live) to avoid any data egress. There are several other options we could have
|
||||||
|
specified here like VM instance type (the default is a 4-core VM with 16 GiB of memory), whether to
|
||||||
|
use spot instance, etc. See the
|
||||||
|
[Coiled Batch docs](https://docs.coiled.io/user_guide/batch.html?utm_source=uv-docs) for more
|
||||||
|
details.
|
||||||
|
|
||||||
Finally we use the [`coiled batch run` CLI](https://docs.coiled.io/user_guide/api.html?utm_source=uv-docs#coiled-batch-run) to run our existing `uv run` command on a cloud VM.
|
Finally we use the
|
||||||
|
[`coiled batch run` CLI](https://docs.coiled.io/user_guide/api.html?utm_source=uv-docs#coiled-batch-run)
|
||||||
|
to run our existing `uv run` command on a cloud VM.
|
||||||
|
|
||||||
```bash hl_lines="1"
|
```bash hl_lines="1"
|
||||||
|
|
||||||
|
|
@ -138,8 +161,10 @@ $ uvx coiled batch run \
|
||||||
uv run process.py
|
uv run process.py
|
||||||
```
|
```
|
||||||
|
|
||||||
The same exact thing that happened locally before now happens on a cloud VM on AWS, only this time the script is faster because we didn't have to transfer any data from S3 to a local laptop.
|
The same exact thing that happened locally before now happens on a cloud VM on AWS, only this time
|
||||||
|
the script is faster because we didn't have to transfer any data from S3 to a local laptop.
|
||||||
|
|
||||||
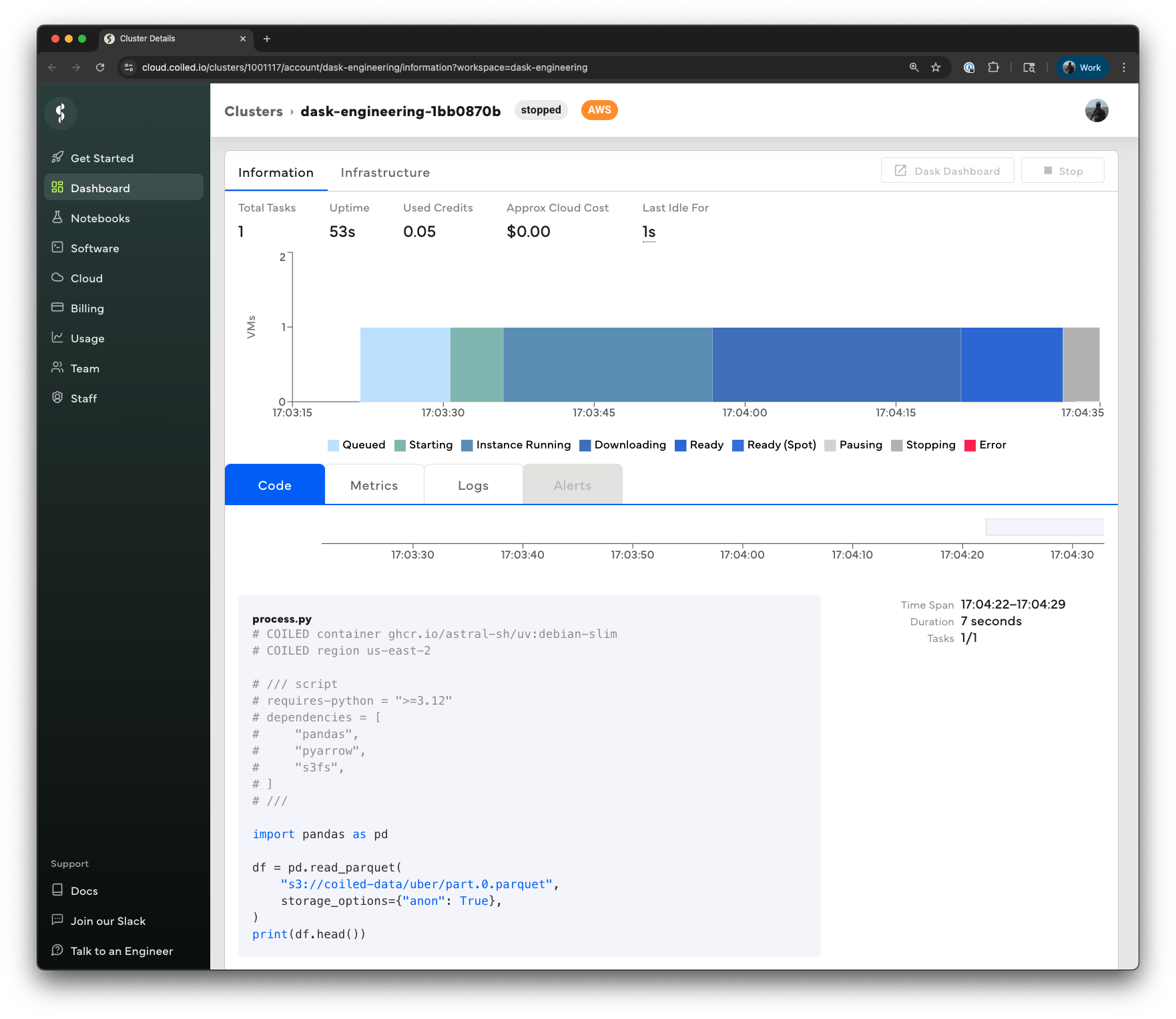
|

|
||||||
|
|
||||||
For more details on Coiled, and how it can be used in other use cases, see the [Coiled documentation](https://docs.coiled.io?utm_source=uv-docs).
|
For more details on Coiled, and how it can be used in other use cases, see the
|
||||||
|
[Coiled documentation](https://docs.coiled.io?utm_source=uv-docs).
|
||||||
|
|
|
||||||
Loading…
Add table
Add a link
Reference in a new issue